
Джозеф Хардер в настоящее время является научным сотрудником Insight Data Science в Нью-Йорке. Во время своей докторской диссертации в Колумбийском университете он использовал компьютерное моделирование для изучения поведения и конструкции программируемых микроскопических частиц.
Заинтересованы в переходе к карьере в области науки о данных? Узнайте больше о программе Insight Data Science Fellows Program в Бостоне, Нью-Йорке, Сиэтле, Кремниевой долине и Торонто или онлайн, подайте заявку сегодня , или подпишитесь на обновления программы.
Писать сложно, а хорошо писать труднее. В дополнение к множеству правил о том, как правильно писать, существует бесконечное количество стилистических решений, которые писатель может сделать, чтобы передать то, что он хочет, так, как он хочет.
«Хорошо писать» также означает разные вещи в разных контекстах. Хорошее письмо в детской книге отличается от хорошего письма в New York Times. Различия в стилях письма между этими двумя контекстами очевидны - автор детской книги использовал бы более короткие предложения и более простые слова, - но есть также стилистические различия в произведениях, предназначенных для чтения одинаковой аудиторией. Статья Buzzfeed News может быть написана менее формально, чем статья в New York Times, хотя обе они сообщают серьезные новости. Эти различия могут быть незначительными и могут быть обнаружены только опытным редактором или писателем.
Мне было любопытно, смогло ли машинное обучение обнаружить эти различия и выявить неявные правила, которые делают средний подход хорошим письмом. В течение трех недель в Insight я создал Fit to Print - инструмент, который изучает стиль написания различных новостных публикаций. Этот инструмент может взять новую статью, найти ее лучшее стилистическое соответствие и выделить некоторые изменения, которые могут привести статью в большее соответствие со стилем написания желаемой публикации. Конечный продукт предназначен для использования в качестве редактора первого прохода, который быстро просматривает материалы, не подходящие для определенной публикации.
Данные статьи и ранние исследования

Чтобы решить вопрос о стиле публикации, я использовал печатные и онлайн-СМИ, потому что есть много публикаций, которые намеренно различаются по одним и тем же темам. Я нашел набор данных, который содержал примерно полтора года статей на главной странице и RSS-потоке из основных публикаций, и решил сосредоточиться на девяти: The New York Times, The Washington Post, Breitbart, Vox, The Atlantic, The National Review, Buzzfeed News. , The Guardian и Fox News. Я включил статьи из всех разделов газеты, потому что редакционные стандарты для разных разделов все равно должны быть внутренне согласованными. Фактически, новости и статьи, которые мы считаем совершенно разными, ближе, чем их названия предполагают, особенно когда набор данных включает публикации с разными стандартами того, сколько явного мировоззрения включать в свои статьи (например, Breitbart против New York Times).
В качестве раннего подтверждения концепции я просмотрел статьи из New York Times, Breitbart и Washington Post. Я взял 5000 статей из этих публикаций и сравнил некоторые особенности стиля письма, которые, как я думал, выявят некоторые различия, такие как количество запятых и количество слов в предложении. Распределения ниже показывают эти две функции для статей из трех тестовых публикаций.

Есть некоторые различия в длине предложений, и New, York, Times, по-видимому, действительно любит, запятые, но различение даже только этих трех публикаций требует гораздо большего количества функций.
Язык и стиль - особенности и моделирование
Чтобы получить вдохновение для новых функций, которые можно добавить в мою модель, я поговорил с некоторыми авторами о том, какие стилистические инструменты они используют, чтобы хорошо писать. Полученные мной отзывы убедили меня в том, что есть измеримые особенности, которые писатели используют, чтобы рассказывать истории определенным образом. Фактически, один друг писатель даже упомянул, что письмо в стиле Нью-Йорк Таймс было настоящим делом. Некоторые из основных характеристик, которые были связаны с хорошим письмом, возникающим в результате этих разговоров, - это использование наречий, структура предложения и повествовательная последовательность. Руководство по стилю New York Times также послужило источником вдохновения благодаря исчерпывающему списку правил того, как писать ясно и эффективно. Это руководство включает предложения по грамматическим практикам, соглашениям о сокращениях и сокращениях и даже советы по использованию конкретных слов (например, попытка или попытка). Было много общего между функциями, найденными в руководстве по стилю, теми, о которых писатели рассказывали мне, и теми, которые использовались в задачах установления авторства. 31 функция, которая в конечном итоге была включена в модель (которую можно увидеть здесь), попала в четыре основные категории: словарный запас, сложность предложения, тон и части частоты речи.
Чтобы построить модель, я попробовал несколько классификаторов, в том числе Naive Bayes, который обычно используется для проблем с атрибуцией авторства, и в конечном итоге остановился на XGBoost. XGBoost был наиболее подходящим классификатором для использования в этом случае, главным образом потому, что были некоторые корреляции в функциях, которые я выбрал, но также потому, что мне нужна была некоторая интерпретируемость результатов, чтобы пользователь мог понять, какие функции важны. Я обучил модель на 80% моих данных, и, хотя я не проводил обширную настройку модели, я оптимизировал ее для обеспечения точности с упором на то, чтобы не переобучать. XGBoost - это модель, состоящая из последовательных учеников дерева за неделю, каждый из которых придает большее значение правильной классификации неправильно классифицированных данных из своего предыдущего дерева. Как и другие модели деревьев, XGBoost склонен к переобучению, поэтому я использовал относительно низкую скорость обучения и убедился, что точность обучающего набора была сопоставима с точностью тестового набора, когда я добавлял слои к дереву.
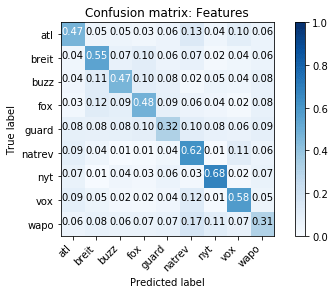
В конечном итоге модель, обученная с использованием 31 функции стиля письма, смогла правильно предсказать источник публикации по крайней мере в 30% случаев и до ~ 70% в случае New York Times, как видно из этой путаницы. матрица. В худшем случае модель все равно в три раза точнее, чем случайное предположение, что кажется обнадеживающим результатом при попытке обнаружить что-то столь же расплывчатое, как стиль письма учреждения.
Конечный продукт - подходит для печати
Конечный продукт Fit to Print - это веб-приложение, в котором пользователь вводит статью и желаемую публикацию. На выходе пользователь получает рекомендации по стилю, который лучше всего подходит для статьи, а также информацию о том, как особенности стиля письма в статье сочетаются со средними значениями этих функций в других публикациях. В качестве примера я беру статью из New York Times о предварительных выборах в Бронксе и хочу сравнить ее со статьями, опубликованными на Vox.

Во-первых, Fit to Print показывает, что эта статья соответствует стилю написания New York Times, а также предоставляет информацию о достоверности классификации. Прокручивая страницу вниз, пользователь видит сравнение функций стиля письма в своей статье и в нужной публикации (где все функции публикации нормализованы до 1). Вот результат для нашего примера:
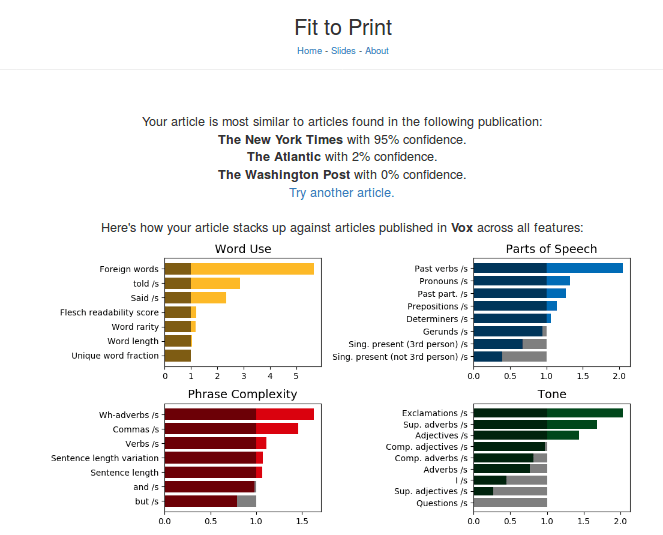
В этой конкретной статье выделяются некоторые интересные аномальные особенности. Две из этих особенностей являются следствием преднамеренного выбора автором, а другая указывает на систематические стилистические различия между New York Times и Vox. Во-первых, статья содержит намного больше иностранных слов, чем типичная статья Vox, что объясняется тем, что одним из кандидатов было имя «Алексадрия Окасио-Кортес», имя, которое читается как «иностранное». Второй вывод, связанный с содержанием, заключается в том, что статья содержит множество восклицательных знаков и наречий в превосходной степени, что, возможно, отражает неожиданность результатов выборов. Наконец, если посмотреть на разницу в частоте использования слов «сказал» и «рассказал», можно выделить институциональную разницу между New York Times и Vox. Vox использует эти слова реже, указывая на то, что они включают в свои статьи меньше интервью, уделяя особое внимание анализу новостей, а не их репортажам.
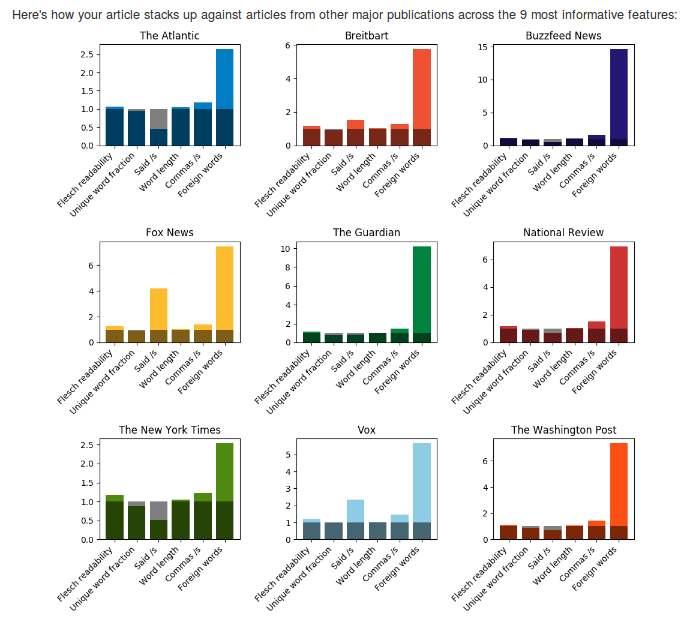
Затем пользователь видит сравнение своей статьи и всех публикаций по шести наиболее информативным функциям модели. В качественном отношении двумя наиболее похожими публикациями, основанными на этих характеристиках, являются New York Times и The Atlantic, что согласуется с прогнозами модели. Несмотря на то, что он ничего не знал о содержании статьи, Fit to Print смог выделить некоторые аномальные, но оправданные решения, сделанные автором, а также значимые различия в стилях письма между двумя основными публикациями.
Дальнейшие улучшения
Я попытался включить другие интерпретируемые функции, в том числе анализ настроений и просмотр изменений стиля в статьях, чтобы измерить поток повествования, но ни один из них не улучшил модель. Однако некоторые более абстрактные функции смогли значительно повысить точность модели. 31 функция, которую я использовал, включала многие части речи 1-граммы, поэтому я решил расширить ее до n-граммов, думая, что будут определенные конструкции фраз, которые сознательно или неосознанно были частью стиля письма публикации. Я сопоставил все подтипы POS с их самым основным типом (например, все глаголы в прошедшем времени обрабатываются как глаголы) и обработал все знаки препинания как идентичные.
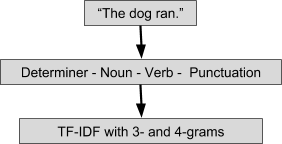
Я подсчитал баллы tf-idf для 3- и 4-граммов POS для каждой статьи и поместил их в случайный лесной классификатор. Объединение прогнозов на основе разработанных функций и моделей tf-idf позволило повысить точность прогнозов на целых 10% и повысить точность для всех публикаций, кроме Buzzfeed и Vox. Эта комбинированная модель повысила точность классификации, но за счет того, что модель стала менее интерпретируемой, поэтому я решил не использовать ее в онлайн-версии инструмента.
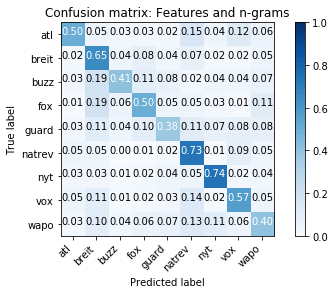
На протяжении всего этого проекта я намеренно игнорировал контент, предпочитая сосредоточиться на том, как пишут публикации, а не на том, о чем они пишут. Если бы у меня было больше времени, я бы включил информацию о содержании статьи, потому что знание того, как публикация пишет по определенным вопросам, может помочь писателю более эффективно оформить статью для конкретной аудитории. Сужение набора данных до статей, похожих на статью пользователя, с использованием подходов тематического моделирования или word2vec, также может дать пользователю более подходящий набор статей, с которыми можно сравнить свой стиль написания.
Забрать
Fit to Print - это, по сути, редактор первого прохода, который использует особенности стиля письма, чтобы выявить различия между новостными публикациями. Однако у этого инструмента есть приложения, которые выходят за рамки просто новостей. Мы можем применить аналогичный метод в отраслях, где важно поддерживать единый стиль, от рекламы до публичных уведомлений или даже до политических выступлений. Одна из самых захватывающих вещей в науке о данных заключается в том, что она может сделать некоторые из неявных правил о том, как устроен мир, явными. Мой проект Insight был направлен на раскрытие некоторых из этих неявных правил, связанных с тем, что делает письмо «хорошим» в различных контекстах.
Заинтересованы в переходе к карьере в области науки о данных? Узнайте больше о программе Insight Data Science Fellows Program в Бостоне, Нью-Йорке, Сиэтле, Кремниевой долине и Торонто или онлайн, подайте заявку сегодня , или подпишитесь на обновления программы.