В первой части этой серии мы рассмотрели основные компоненты модели Transformer - Multi Head Внимание и Positionwise Feedforward. Теперь посмотрим, как они работают вместе.
Собираем все вместе
PyTorch упрощает объектно-ориентированный дизайн с nn.Module, поэтому мы можем вкладывать компоненты, как в статье. Следуя их терминологии слой и подслой, я структурировал код в трех файлах:
- sublayers.py: определяет самые внутренние компоненты, а именно
MultiHeadAttentionиPositionwiseFeedforward. Они используются как слоями кодировщика, так и уровнями декодера. - Layers.py: Определяет один уровень блоков кодировщика и декодера, называемых
EncoderLayerиDecoderLayerсоответственно. На блок-схеме это серые области. - main.py: содержит определения блоков кодирования и декодирования верхнего уровня, называемых
EncoderиDecoder. Он обрабатывает такие вещи, как несколько уровней, генерацию сигналов синхронизации и маски внимания, среди прочего.
Давайте рассмотрим каждую из их forward() функций, начиная с EncoderLayer:
Я не буду рассказывать о LayerNorm, поскольку это стандартное дело. Ознакомиться с полной реализацией можно здесь. Важный момент, приведенный выше, - это призыв к многоголовому вниманию:
y = self.multi_head_attention(x_norm, x_norm, x_norm)
Сделайте запросы, ключи и значения одинаковыми, и вуаля мы получим самовнимание! В наши дни этот термин часто используется, и теперь вы знаете, что это не что-то особенное. Это компонент, который заменяет повторяющиеся и сверточные слои, и, как утверждают авторы в своей статье, он более быстрый и мощный. Выпадение и остаточные соединения объединяются за один шаг:
x = self.dropout(x + y)
Обратите внимание, что остаточный ввод выполняется до нормализации слоя. DecoderLayer похож:
Первое отличие, которое мы здесь отметим, заключается в том, что DecoderLayer принимает входные данные как кортеж, состоящий из входов декодера, а также выходов кодировщика. Я использовал кортеж, чтобы легко передавать входные данные через несколько слоев с помощью nn.Sequential. Выходы энкодера требуют внимания.
DecoderLayer дважды выполняет внимание на нескольких головах. Сначала он выполняет самовнимание, как EncoderLayer, но запросы «замаскированы» (подробнее об этом позже, я обещаю). Второй вызов использует выходы кодировщика как ключи и значения:
y = self.multi_head_attention_enc_dec(x_norm, encoder_outputs, encoder_outputs)
Запросы поступают из выходов самовнимания (с некоторой пост-обработкой). Напомню еще раз, что запросы для всех временных шагов декодера доступны вместе во время обучения и оценки из-за природы Transformer. Для повторяющейся сети вы можете получать запрос только на одном временном шаге за раз, поскольку запрос на следующем временном шаге зависит от выходов внимания на текущем временном шаге - это основной фактор, замедляющий повторяющиеся сети и затрудняющий их распараллеливание. Однако во время логического вывода Transformer также должен декодировать по одному временному шагу за раз. Единственный способ сделать это - запустить декодер несколько раз, каждый раз расширяя входы декодера новыми полученными выходами. Это медленный процесс, требующий многократной обработки одних и тех же входных данных. Чтобы частично ускорить это, реализация Transformer в Tensorflow кэширует выходные данные о внимании для каждого временного шага (я еще не реализовал кеширование в PyTorch).
Наконец, на верхнем уровне у нас есть Encoder и Decoder:
Проекция внедрения линейно проецирует выходные данные внедрения (внешние по отношению к трансформатору) к общему скрытому размеру:
self.embedding_proj = nn.Linear(embedding_size, hidden_size, bias=False)
Затем добавляется «сигнал синхронизации», чтобы модель могла лучше отслеживать порядок следования. Мы поговорим об этом в следующем разделе. Слой кодировщика применяется несколько раз с использованием nn.Sequential:
self.enc = nn.Sequential(*[EncoderLayer(*params) for l in range(num_layers)])
params - это набор гиперпараметров, идентичный для каждого слоя. Реализация Decoder очень похожа:
Как и в случае с DecoderLayer, основное отличие состоит в том, что с выходов энкодера поступает дополнительный входной сигнал. Он объединяется с входами декодера в виде кортежа и передается в компонент DecoderLayer:
y, _ = self.dec((x, encoder_output))
Конечные выходные данные Decoder (или Encoder для нашей задачи) проходят через выходной слой, который сначала проецируется на измерение, равное выходному словарю. После этого может быть слой Softmax или, в нашем случае, слой CRF. На этом конвейер завершен! Теперь о дополнительных трюках ..
Скрытое внимание - не заглядывать в будущее
Я упомянул, что расскажу о маске смещения внимания позже, просматривая код MultiHeadAttention. Для таких задач, как перевод, декодер использует предыдущие выходные данные в качестве входных данных для прогнозирования следующего выхода. Во время обучения быстрый способ получить предыдущие выходные данные - это сдвинуть метки обучения вправо (первый временной шаг получает специальный символ) и передать их в качестве входных данных декодера - метод, известный как принудительное принуждение учителя на языке машинного обучения. Однако это представляет проблему для декодера Transformer, поскольку он может «обмануть», используя входные данные из будущих временных шагов. Места, где может произойти короткое замыкание, - это шаг самовнимания и оба шага с прямой связью. (Можете ли вы понять, почему этого не может произойти на этапе обычного внимания?)
На этапе самовнимания мы передаем значения из всех временных шагов компоненту MultiHeadAttention. Напомним, что мы выполняем взвешенную линейную комбинацию входных данных Values :
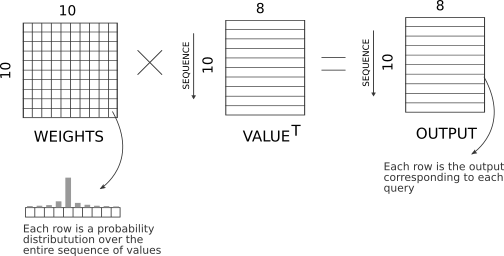
Рассмотрим первую строку OUTPUT на приведенной выше диаграмме. Это соответствует выходу внимания в момент времени t = 1. Но он вычисляется от значений вплоть до t = 10, которые являются будущими временными шагами. Чтобы предотвратить чтение этих будущих значений, мы обнуляем все веса в тензоре WEIGHTS над главной диагональю. Это гарантирует, что будущие ценности не смогут проникнуть внутрь:
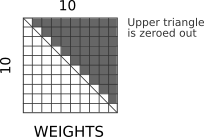
На практике мы не обнуляем весовой тензор напрямую, так как это потребует дополнительной нормализации, чтобы гарантировать, что все вероятности в сумме будут равны единице. Вместо этого мы добавляем отрицательную бесконечность к верхнему треугольнику перед Softmax; после возведения в степень эти значения становятся нулевыми. Также мы предварительно вычисляем эту матрицу, если известна максимальная длина:
Обрезанная версия маски применяется в компоненте MultiHeadAttention:
if self.bias_mask is not None: logits += Variable( self.bias_mask[:, :, :logits.shape[-2], :logits.shape[-1]] .type_as(logits.data))
Аналогичная проблема возникает в компоненте PositionwiseFeedforward, если мы используем сверточные слои. Одномерная свертка с фильтром шириной 3 будет обращаться к входу в момент времени t + 1 для вычисления выходных данных в момент времени t:

Это связано с тем, что входные данные автоматически дополняются, когда мы хотим, чтобы длина выходной последовательности оставалась такой же, как длина входной последовательности. Небольшое изменение заполнения решает проблему:

Теперь вывод в момент времени t будет зависеть только от входов в момент времени t, t-1 и t-2. nn.Conv1d API в PyTorch не поддерживает этот тип заполнения, поэтому мы делаем это сами:
Для нашей задачи маркировки последовательностей мы используем только кодировочную часть трансформатора и не подаем выходные сигналы обратно в кодировщик. Поэтому мы не будем использовать ни маску смещения, ни отступы по левому краю. Дальше последний трюк.
Позиционное кодирование - хронометрист
Неотъемлемой особенностью рекуррентных нейронных сетей является их способность отслеживать порядок входных последовательностей из-за внутреннего состояния, которое они поддерживают. Поскольку повторяющиеся слои отсутствуют в Transformer, он не может легко отличить вход на одном временном шаге от другого. Чтобы восполнить эту нехватку состояния, необходимо добавить дополнительную позиционную информацию, чтобы каждый временной шаг был уникальным. В более ранней работе под названием Изучение сверточной последовательности в последовательность использовались позиционные вложения, которые в основном добавляли случайные векторы, уникальные для каждого временного шага. Затем модель может научиться определять абсолютные позиции входов. Создатели Transformer усовершенствовали эту технику, добавив синусоиды, которые, как они утверждают, также могут отслеживать относительное положение, поскольку синусоиды являются циклическими функциями. В нашей реализации используются синусоиды, адаптированные прямо из TensorFlow:
Здесь channels - скрытый размер нашей модели. Начиная с шкалы времени 1, мы генерируем сигналы sin и cos с экспоненциально увеличивающейся длиной волны или уменьшающейся частотой (отсюда -log_timescale_increment в строке 13) для каждого измерения, пока оно не достигнет 10 000. Я считаю, что эти числа были получены экспериментальным путем, поэтому их, возможно, придется изменить для новой задачи. Как и при маскировании смещения, мы предварительно вычисляем эти значения и добавляем обрезанные версии во входные данные (после встраивания) во время выполнения:
x += Variable(
self.timing_signal[:, :inputs.shape[1], :]
.type_as(inputs.data))
После применения этих двух приемов наш Трансформер наконец-то готов. Давайте посмотрим на это в действии прямо сейчас!
Трансформер против BiLSTM - Противостояние
Наша модель Transformer будет идти против хорошо известной двунаправленной LSTM в задаче CoNLL 2000 chunking. Это довольно старая задача, поскольку современные значения F1 колеблются в пределах 94–95%. В отличие от топовых моделей, единственная функция ввода, которую мы собираемся использовать, - это необработанный текст - без каких-либо речевых тегов, функций орфографии или заглавных букв. Однако мы будем использовать внешние вложения слов (GloVe 200D и Char N-Grams, если быть точными) и вложения символов. Обе модели будут использовать слой условного случайного поля (CRF) на выходной стороне. В этом эксперименте мы будем использовать только кодировочную часть преобразователя, поскольку это задача сопоставления один-к-одному.
Прежде чем мы сможем обучить эти модели, необходимо сделать множество вещей. Для удобства я написал небольшой фреймворк, который позаботится о шаблоне. Я называю его TorchNLP , и он выполняет следующие функции:
- Обработка конвейера данных (использует TorchText под капотом)
- Загрузка и сохранение моделей
- Обучающие модели с настраиваемыми гиперпараметрами
- Оценка моделей с помощью таких показателей, как точность, F1 и т. Д.
Трансформатор и двунаправленный LSTM вместе с общими компонентами, такими как CRF, уже встроены в структуру, поэтому все, что нам нужно сделать, это провести эксперименты.
Установка очень проста. Однако для его запуска вам понадобится Python 3.5+. Клонировать TorchNLP с GitHub:
git clone https://github.com/kolloldas/torchnlp.git
Настройте PyTorch с поддержкой графического процессора или без нее (желательно в новой виртуальной среде Python 3). Заходим в корень проекта TorchNLP и устанавливаем зависимости:
pip install -r requirements.txt
Это все, что нужно для установки. Запустите задачу разбиения на части:
python -i -m torchnlp.chunk
Это загрузит среду для фрагментации:
Task: Chunking (Shallow parsing) Available models: ------------------- TransformerTagger Sequence tagger using the Transformer network (https://arxiv.org/pdf/1706.03762.pdf) Specifically it uses the Encoder module. For character embeddings (per word) it uses the same Encoder module above which an additive (Bahdanau) self-attention layer is added BiLSTMTagger Sequence tagger using bidirectional LSTM. For character embeddings per word uses (unidirectional) LSTM Available datasets: ------------------- conll2000: Conll 2000 (Chunking) >>>
(Если на этом этапе вы получите какие-либо ошибки, это означает, что с вашей установкой что-то пошло не так. Пожалуйста, объясните ошибку в разделе комментариев, и я буду рад помочь.)
Посмотрим, какие гиперпараметры есть у наших моделей. Здесь BiLSTM:
>>> hparams_lstm_chunk() Hyperparameters: dropout=0.5 learning_rate_decay=noam_step optimizer_adam_beta2=0.98 optimizer_adam_beta1=0.9 embedding_size_word=300 learning_rate_warmup_steps=100 hidden_size=100 embedding_size_tags=100 embedding_size_char=25 learning_rate=0.05 max_length=256 batch_size=100 num_hidden_layers=2 use_crf=True embedding_size_char_per_word=25
И Трансформатор:
>>> hparams_transformer_chunk() Hyperparameters: relu_dropout=0.2 learning_rate_decay=noam_step optimizer_adam_beta2=0.98 optimizer_adam_beta1=0.9 embedding_size_word=300 attention_key_channels=0 filter_size_char=64 embedding_size_char=16 embedding_size_tags=100 embedding_size_char_per_word=100 dropout=0.2 filter_size=128 use_crf=True num_hidden_layers=2 attention_value_channels=0 hidden_size=128 input_dropout=0.2 learning_rate_warmup_steps=500 num_heads=4 learning_rate=0.2 max_length=256 batch_size=100 attention_dropout=0.2
У Transformer гораздо больше ручек, чем у модели BiLSTM. Также обратите внимание, что она намного меньше по параметрам, чем исходная модель, поскольку сама задача настолько мала. Трансформер пойдет первым. Начать обучение:
>>> train('chunking', TransformerTagger, conll2000)
Вы должны увидеть, что в первую очередь загружаются и извлекаются наборы данных и вложения слов. (Имейте в виду, что вложения слов имеют размер около 2 ГБ.) После этого обучение начнется с полосы, показывающей прогресс в каждую эпоху. Обучение остановится автоматически, как только значение F1 на данных проверки достигнет пика (с использованием ранней остановки). Для меня это было после 35 эпох:
INFO:torchnlp.common.train:Epoch 35 (2754) INFO:torchnlp.common.train:Train Loss: 1.79630 INFO:torchnlp.common.train:Validation metrics: INFO:torchnlp.common.train:loss=2.21440, F1=0.94471, acc-seq=0.62640, recall=0.94353, acc=0.96548, precision=0.94589 INFO:torchnlp.common.train:Early stopping at iteration 2430, epoch 29, F1=0.94504
Выглядит неплохо. Очередь BiLSTM:
>>> train('chunking', BiLSTMTagger, conll2000)
...
INFO:torchnlp.common.train:Epoch 26 (2025)
INFO:torchnlp.common.train:Train Loss: 0.68408
INFO:torchnlp.common.train:Validation metrics:
INFO:torchnlp.common.train:loss=2.32462, F1=0.94619,
acc-seq=0.61521, recall=0.94749, acc=0.96784, precision=0.94488
INFO:torchnlp.common.train:Early stopping at iteration 1701, epoch 20, F1=0.94669
Хм, у BiLSTM F1 немного лучше. К тому же он быстрее сходился. Пора повернуть некоторые из этих ручек на трансформаторе. Переход на 2 головы:
>>> h2 = hparams_transformer_chunk().update(num_heads=2)
>>> train('chunking_h2', TransformerTagger, conll2000, hparams=h2)
...
INFO:torchnlp.common.train:Epoch 54 (4293)
INFO:torchnlp.common.train:Train Loss: 1.65368
INFO:torchnlp.common.train:Validation metrics:
INFO:torchnlp.common.train:loss=2.19627, F1=0.94715, acc-seq=0.63087, recall=0.94915, acc=0.96771, precision=0.94515
INFO:torchnlp.common.train:Early stopping at iteration 3969, epoch 48, F1=0.94746
Хорошо, теперь впереди Трансформер. Мы могли бы продолжать настраивать гиперпараметры таким образом в течение длительного времени (в конце концов, именно об этом и ведутся исследования), но без роскоши кластера глубокого обучения, позволяющего прокручивать множество комбинаций, будет трудно добиться прогресса. Оценим обе модели на тестовой выборке. BiLSTM получает:
>>> evaluate('chunking', BiLSTMTagger, conll2000, 'test')
...
test set evaluation: chunking-BiLSTMTagger
loss=3.19308, F1=0.94238, acc-seq=0.61133, recall=0.94206, acc=0.96500, precision=0.94269
94,24% F1. И Трансформер получает:
>>> evaluate('chunking_h2', TransformerTagger, conll2000, 'test')
test set evaluation: chunking_l2-TransformerTagger
loss=2.97885, F1=0.94319, acc-seq=0.61581, recall=0.94424, acc=0.96541, precision=0.94215
94,32% F1 😑. Это слишком близко для ответа, поскольку 0,1% находится в пределах погрешности. Если мы не проведем большое количество экспериментов, мы не сможем назвать это явной победой. На данный момент ничья.

Я бы посоветовал вам поиграть с гиперпараметрами или даже изменить архитектуру, чтобы увидеть, может ли Transformer работать лучше. Если вы выиграете джекпот, дайте мне знать!
Уроки выучены
Наш самодельный Transformer не смог бы значительно превзойти BiLSTM. Хотя у него было меньше обучаемых параметров примерно на 200 КБ меньше, чем у BiLSTM, для схождения требовалось больше времени. Итак, что мы можем сказать об общей архитектуре Transformer?
В ходе экспериментов я обнаружил, что Transformer работает хуже, если мы используем линейные слои вместо сверточных в компоненте PositionwiseFeedforward. Помните, что для этой задачи мы использовали только половину преобразователя Encoder (я пытался добавить декодер, это не улучшило результатов). Так что у меня есть подозрение, что самовнимание само по себе не может делать входные данные на нескольких временных шагах, взаимодействовать мультипликативно, что может уловить более сложное явление . Он заботится о парных мультипликативных взаимодействиях между разными временными шагами, но не обрабатывает, скажем, 3–4 шага вместе. Использование сверточных слоев с размером ядра 3 может частично решить эту проблему, но взаимодействие между ними носит аддитивный характер. Наличие двух слоев вместо одного также улучшило F1, поскольку позволяло более чем двум временным шагам взаимодействовать нелинейно. Но они слабее по сравнению с рекуррентной сетью, которая имеет сильные нелинейные взаимодействия между несколькими ближайшими временными шагами. Так что, в конце концов, успехи, которые Трансформатор сделал благодаря собственному вниманию и комбинации упреждения, вероятно, были потеряны из-за этой неспособности. Опять же, необходимы дополнительные эксперименты.
В ближайшем будущем, возможно, появится гибридная модель, которая выполняет странную комбинаторную акробатику для обработки многошаговых взаимодействий, но при этом остается быстрой. Кто знает, может быть, он уже находится в разработке в Google!
ПРИМЕЧАНИЕ. Я упустил некоторые детали реализации (например, график скорости обучения Ноама и т. Д.), Чтобы сохранить разумную длину статьи. Вы можете просмотреть код, чтобы понять эти части, которые, я надеюсь, не требуют пояснений. Если у вас есть какие-либо конкретные вопросы, задавайте их в разделе комментариев, и я постараюсь на них ответить.