
Авторегрессионное (AR) языковое моделирование и автокодирование (AE) — две успешные цели предварительного обучения для нейронных сетей, используемых в трансферном обучении для НЛП. Моделирование языка AR предсказывает следующее слово в последовательности на основе предыдущих слов, но не может обрабатывать глубокий двунаправленный контекст, который важен для таких задач, как анализ настроений и ответы на вопросы. AE, с другой стороны, восстанавливает исходные данные из поврежденных данных и используется в BERT. Однако у BERT есть некоторые ограничения, например, BERT предполагает, что предсказанные токены независимы друг от друга, учитывая незамаскированные токены, что является чрезмерным упрощением, поскольку в естественном языке преобладает дальняя зависимость высокого порядка.
XLNet предлагает новый метод предварительной подготовки языковых моделей, который сочетает в себе идеи из целей AR и AE, избегая при этом их ограничений, и может улучшить их производительность в широком диапазоне задач понимания естественного языка (NLU).
Моделирование языка перестановок
Ключевая идея XLNet заключается в использовании подхода, основанного на перестановках, который позволяет модели учиться на всех возможных комбинациях входных токенов, а не только на одном фиксированном порядке. Это достигается за счет обучения модели прогнозированию вероятности токена с учетом всех других токенов во входной последовательности, независимо от их положения. Этот подход называется «моделирование языка перестановок» и является расширением подхода авторегрессионного моделирования языка, используемого в предыдущих моделях.
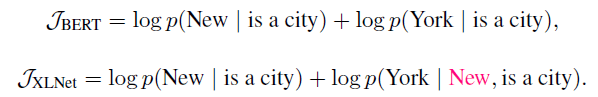
XLNet также использует модифицированную версию архитектуры Transformer, называемую «Transformer-XL», которая предназначена для захвата долгосрочных зависимостей во входной последовательности. Это достигается за счет использования механизма повторения на уровне сегмента, который позволяет модели сохранять память о предыдущем сегменте при обработке текущего сегмента.
Оценка
XLNet объединяет BooksCorpus, English Wikipedia, Giga5, ClueWeb 2012-B и Common Crawl для предварительной подготовки. Токенизация достигается с помощью SentencePiece. чтобы получить 2,78 млрд, 1,09 млрд, 4,75 млрд, 4,30 млрд и 19,97 млрд фрагментов подслов для Wikipedia, BooksCorpus, Giga5, ClueWeb и Common Crawl соответственно, что в сумме составляет 32,89 млрд.
В XLNet-Large используются те же гиперпараметры архитектуры, что и в BERT-Large. XLNet-Large не смогла использовать дополнительную шкалу данных, поэтому для проведения объективного сравнения с BERT был использован XLNet-Base (аналог BERT-Base). Это также означает, что для предварительной подготовки использовались только BooksCorpus и английская Wikipedia.





- Для задач явного рассуждения, таких как SQuAD и RACE, которые включают более длинный контекст, прирост производительности XLNet обычно больше. Это превосходство в работе с более длинным контекстом может исходить от магистрали Transformer-XL в XLNet.
- Для задач классификации, которые уже имеют множество контролируемых примеров, таких как MNLI (> 390 тыс.), Yelp (> 560 тыс.) и Amazon (> 3 млн.), XLNet по-прежнему дает существенный выигрыш.
Бумага
XLNet: Обобщенная авторегрессионная предварительная подготовка для понимания языка 1906.08237
Просмотреть все темы этой серии здесь