Обработка естественного языка (NLP) — это область, связанная со способностью компьютера понимать, анализировать, манипулировать и потенциально генерировать человеческий язык.
Пример: спам-фильтр, автозаполнение, автозамена
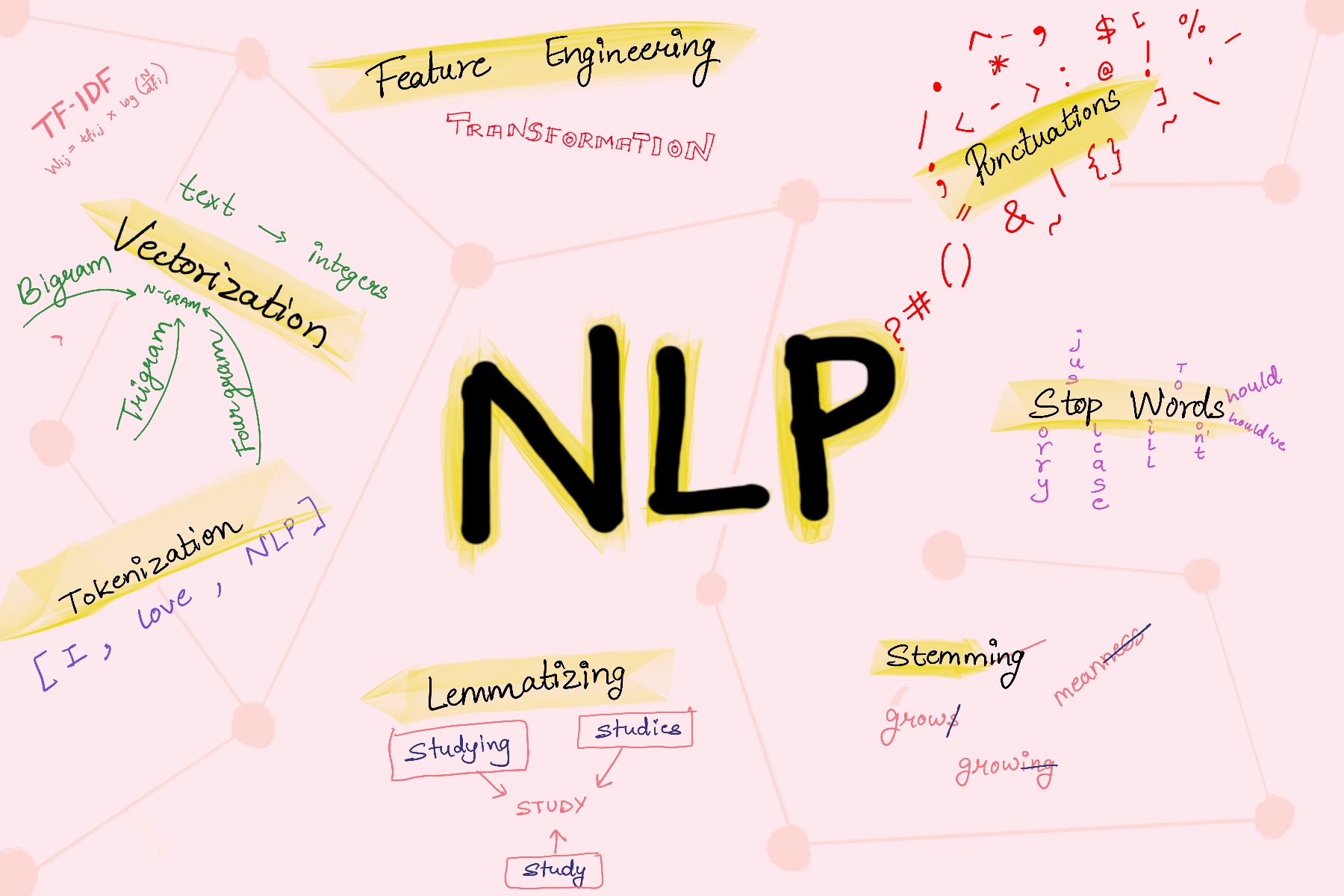
Набор инструментов естественного языка (NLTK)
Вот темы, которые мы рассмотрим сегодня:
- Удалить знаки препинания
- Токенизация
- Удалить стоп-слова
- Стемминг
- лемматизация
- Векторизация
- Разработка функций
Преобразования
Удалить знаки препинания
Мы должны удалить зашумленные текстовые данные, прежде чем передавать их в модель машинного обучения.


Токенизация
Преобразуйте текстовые данные в векторы токена

Удалить стоп-слова:
Часто используемые слова, которые можно игнорировать, не добавляя к тексту релевантной информации.



Вывод
- Процесс сокращения флективных (или иногда производных) слов до их основы или корня слова.
- Хотя они могут иметь разные аффиксы, слова, имеющие одинаковую основу, имеют сходное семантическое значение.
- Просто отсекает конец слова с помощью эвристики без понимания контекста, в котором слово используется.
- Типы Stemmer:
Stemmer Porter
Stemmer Snowball
Stemmer Lancaster
Stemmer на основе регулярных выражений


Лемматизация
- Процесс группировки флективных форм слова, чтобы их можно было проанализировать как единый термин, определяемый леммой слова.
- Лемматизация — это использование словарного анализа слов для удаления флективных окончаний и возврата к словарной форме слова.
- Лемматизатор WordNet()
Лучше, чем стеммер, но требует больше времени для запуска



Векторизация:
ВЕКТОРИЗАЦИЯ: процесс кодирования текста как целых чисел для создания векторов признаков.
ВЕКТОР ПРИЗНАКОВ: n-мерный вектор числовых признаков, представляющих некоторый объект.
МАТРИЦА ТЕРМИНОВ ДОКУМЕНТОВ:
столбец: слова
строка: количество документов/сообщений в данных.
значение: количество раз появления этого слова.
Типы векторизации:
- Векторизация счета
- N-граммы
- Term Frequency — обратная частота документа (TF-IDF)
- СЧЕТ ВЕКТОРИЗАЦИИ: создает матрицу терминов документа, а затем просто подсчитывает, сколько раз каждое слово появляется в данном документе.

2. N-ГРАММЫ: матрица терминов документа, в которой счетчики по-прежнему занимают ячейку, но вместо столбцов, представляющих отдельные термины, они представляют все комбинации соседних терминов длины n в вашем тексте.


РАЗРЯДНАЯ МАТРИЦА: матрица, в которой большинство элементов равно 0. В интересах эффективного хранения разреженная матрица будет храниться путем хранения только местоположения ненулевых элементов.

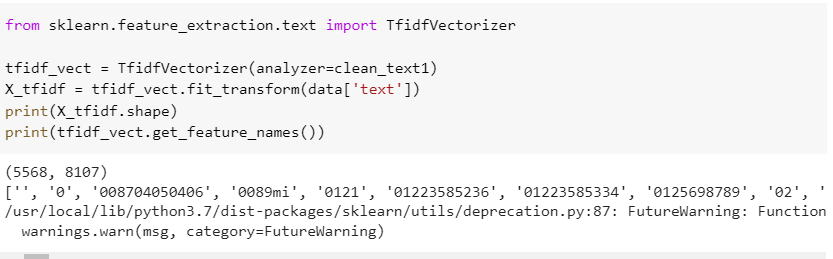
3. TF-IDF (Термин частота-обратная частота документа)
TF-IDF создает матрицу терминов документа, в которой по-прежнему есть одна строка для каждого текстового сообщения, а столбцы по-прежнему представляют отдельные уникальные термины. Но вместо ячеек, представляющих количество, ячейки представляют собой взвешивание, которое предназначено для определения того, насколько важно слово для отдельного текстового сообщения.
Как определяется вес? Используя эту формулу



Разработка функций
Создание новых функций или преобразование существующих функций, чтобы получить максимальную отдачу от ваших данных
Создание новых функций
- Длина текстового поля
- % знаков препинания в тексте
- % символов, написанных с заглавной буквы
Преобразования
- Степенные преобразования (квадрат, квадратный корень и т. д.)
- Стандартизация данных
- Длина текстового сообщения
Гипотеза: спам-сообщения, как правило, длиннее, чем настоящие текстовые сообщения.

2. Процент каждого текстового сообщения, содержащего знаки препинания
Гипотеза: в настоящих текстовых сообщениях используется меньше знаков препинания, чем в спаме.

Оцените созданные функции
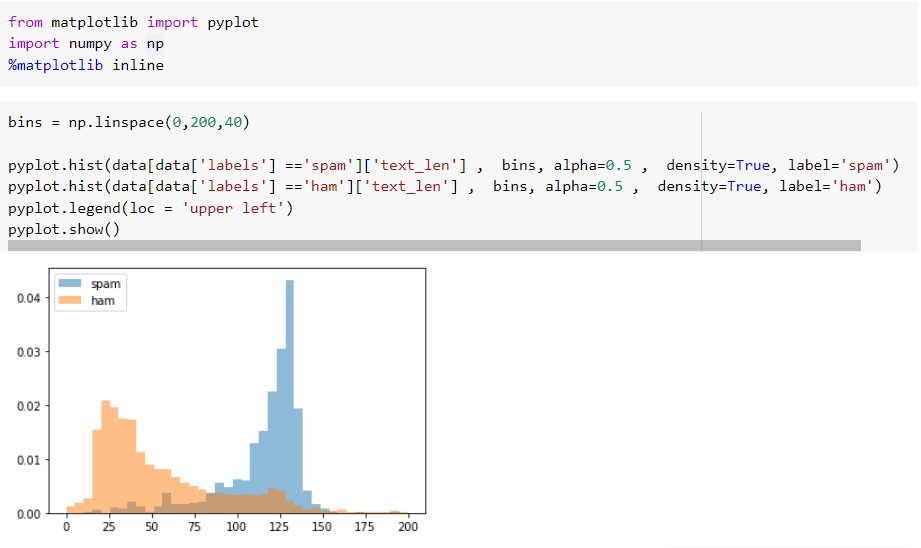

Гипотеза: что спам-сообщения, как правило, длиннее, чем не-спам-сообщения, кажется верной на основе этой оценки, эта функция, вероятно, придаст некоторую ценность модели.
Гипотеза: что сообщения радиолюбителей содержат меньше знаков препинания, чем спам, кажется неточным, не совсем ясно, будет ли эта функция ценной для модели.
Преобразования

Процесс преобразования:
- Определите, какой диапазон показателей тестировать
- Применить каждое преобразование к каждому значению выбранного признака
- Используйте некоторые критерии, чтобы определить, какое из преобразований дает наилучшее распределение.


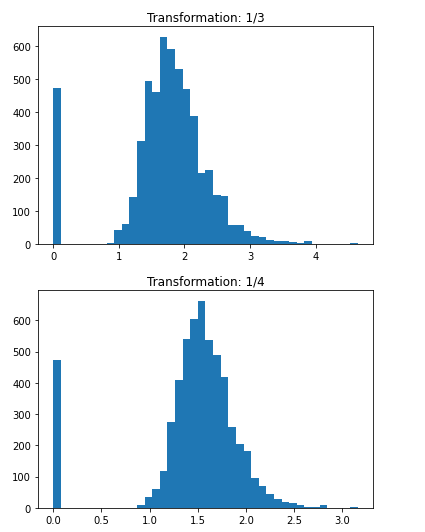

Выберите преобразование, которое будет либо одной четвертой, либо одной пятой.
Концепции машинного обучения: продолжение следует…
Спасибо, что прочитали эту статью! Пожалуйста, похлопайте 👏 или оставьте комментарий 💬, если эта статья вам помогла!